

前回、売上実績サンプルデータについてSARIMA(季節自己回帰和分移動平均)を用いて売上予測を行いました。

結果はなかなかでしたが、今回はランダムフォレストを用いて将来の売上予測をしてみたいと思います。
ランダムフォレストの準備
まずは、いつも同様、Google Colaboratoryへアクセスし、Google DriveのマウントとMatplotlibの日本語表示のためのフォントインストールおよびキャッシュの削除、売上実績サンプルエクセルデータのDataframeへの読み込みまでを済ませておきます。なお、今までのプログラムもそうですが、matplotlibで日本語を表示させるためにはフォントキャッシュを削除後一度ランタイムを再起動する必要があるようです。
from google.colab import drive
drive.mount(‘/content/drive’)
!apt-get -y install fonts-ipafont-gothic
!rm /root/.cache/matplotlib/fontlist-v310.json
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rcParams
import matplotlib
%matplotlib inline
filepath=”/content/drive/My Drive/Colab Notebooks/売上実績sample.xlsx”
df_a = pd.read_excel(filepath,usecols=[0,1,2])
df_a[‘年月’]=df_a[‘年’].astype(str) + ‘/’ + df_a[‘月’].astype(str)
df_a = df_a.loc[:,[‘年月’,’売上高’]]
グラフ作成時のx座標(日付)表示のための下準備をしておきます。
raw_data = np.array(df_a.iloc[:,1].astype(‘float32’))
u_dateym = pd.to_datetime(df_a.iloc[:,0])
# 日付
#リスト作成
further_date = []
dm_num=len(df_a[‘年月’])
dm_last=u_dateym.iloc[dm_num-1]
for i in range(1,f_future_d + 1):
further_date.append(dm_last + relativedelta(months=i))
#日付結合u_dateym = pd.concat([u_dateym,pd.Series(data = further_date)],axis=0)
過去のlength(ここでは12ヶ月)の売上データをインプットとして、次の月の売上を予測する形になるため、Xはlength(ここでは12)の売上、yには次の月の売上を入れたリストを作っておきます。
# Make input data
x, y = [], []
for i in range(len(raw_data)-length-future_d):
x.append(raw_data[i:i + length])
y.append(raw_data[i + length])
ランダムフォレストとは?
ランダムフォレストは弱学習器の決定木をいくつか束ね(アンサンブル)で、それらの結果の多数決をとるもの。3本の矢といった感じでしょうか・・・。ランダムフォレストにはいくつか専門用語がでてきたのでまとめてみました。
ブートストラップ:ランダムフォレストはいくつかの弱学習器で学習するが、その学習の際のデータの抽出方法で重複を許す。
アンサンブル手法:複数の学習器を組み合わせてより良い予測を得る手法。
以下は代表的なアンサンブル手法
バギング:弱学習器を複数用いてその結果の多数決をとる。並列処理できるので実行が早い。
ブースティング:弱学習器を順番に弱点を補いながら実行し、最後に多数決をとる。精度があがる。
スタッキング:あるモデルの結果から次のモデルを作る。精度があがる。
今回は、バギングで売上予測をしてみたいと思います。
必要なライブラリをインポートする
ランダムフォレストは分類にも回帰は使えるようで、scikit-leanライブラリにもそれぞれのメソッドが用意されていました。ランダムフォレストでの回帰に必要なライブラリをインポートしておきます。売上データを学習用、テスト用に分けるためのtrain_test_splitと、最適なモデルの変数(ハイパーパラメーター)を探索してくれるGridSearchCVもインポートしておきます。
# 必要なライブラリのインポート
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
最適な決定木数を決める
GridSearchCVを用いて最適なハイパーパラメーターを決定します。どのパラメーターを対象にするかは決めないといけないようなので、今回は最も影響が大きそうな決定木の数を決めてみたいと思います。探索する決定木の数は3,10,50,100,500,1000,5000,10000にしてみました。当然ですが探索する個数を増やすほど時間がかかります。また、調整方法は下のようなものがありますが、今回はグリッドサーチで決定してみたいと思います。
調整方法
グリッドサーチ:決められた範囲を総当りに探索
ランダムサーチ:投入するパラメータをランダムに変えて試す
#訓練用とテストデータにわける
(x_train, x_test, y_train, y_test) = train_test_split(x, y, test_size = 0.2)
# 動かすパラメータを明示的に表示、今回は決定木の数を変えてみるparams = {‘n_estimators’ : [3, 10, 50, 100, 500,1000, 5000,10000], ‘n_jobs’: [-1]}
# モデルにインスタンス生成
t_forest = RandomForestRegressor()
# ハイパーパラメータ探索cv = GridSearchCV(t_forest, params, cv = 10, scoring= ‘neg_mean_squared_error’, n_jobs =1)
cv.fit(x_train, y_train)
モデルの作成と学習
GridSearchCVの結果から各決定木数のスコア一覧を取得して、一番いい決定木数をセットし学習させます。
# スコアの一覧を取得
gs_result = pd.DataFrame.from_dict(cv.cv_results_)
#一番いい決定木数をセットbest_d = gs_result[gs_result.rank_test_score == 1].values[0,4]
#学習
r_forest = RandomForestRegressor(n_estimators=best_d)
r_forest.fit(x, y)
fit時に出力されるRandomForestRegressorのハイパーパラメーターの値から、一番スコアがよかった決定木数は50だったようです。
RandomForestRegressor(bootstrap=True, ccp_alpha=0.0, criterion=’mse’, max_depth=None, max_features=’auto’, max_leaf_nodes=None, max_samples=None, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=50, n_jobs=None, oob_score=False, random_state=None, verbose=0, warm_start=False)
モデルを使って将来を予測
作成したモデルを使って将来の売り上げを予想します。作成したもでるr_forestを使ってfutureリストに予測した売り上げを入れていきます。
future = []
x_series = x[-1]
for i in range(len(raw_data)+1, len(raw_data)+ f_future_d + 1):
future_d = r_forest.predict([x_series])
future = np.append(future, future_d)
x_series = np.append(x_series, future_d)
x_series = x_series[1:]
いよいよグラフ化
下のコードで、前回同様グラフ化してみます。
plt.rcParams[‘font.family’] = ‘IPAPGothic’
plt.xticks(np.arange(0, len(u_dateym) + 1, 12),rotation=70)
plt.title(“売上サンプル”, fontsize = 16)
plt.xlabel(‘年月’)
plt.ylabel(‘売上高(億円)’)
plt.plot(u_dateym.iloc[0:dm_num].dt.strftime(‘%Y/%m’), df_a[‘売上高’], color=”b”, label=’売上実績’)
plt.plot(pd.Series(data=further_date).dt.strftime(‘%Y/%m’), future, color=”y”, label=”予測”)
plt.legend()
plt.savefig(“predict-randomforest.png”,dpi=200, bbox_inches=”tight”, pad_inches=0.1)
plt.show()
plt.close()
出力結果はこちらです。
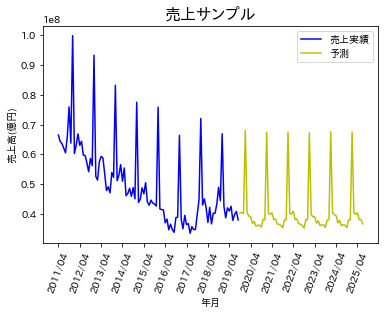
トレンドの予測はある程度できていそうですが、実績データは毎年の売上ピークにでっこみ引っ込みがありますが、予測はほぼフラットになっています。この点は、他のパラメーターを変更すれば改善するのかもしれません。次回はニューラルネット(LSTM)を用いて予測してみたいと思います。
データマーケティングはプロへお任せください
当社ではデータマーケティングやそのツールの活用に長けたコンサルタントがおります。もし利活用にお困りのことがあればぜひ、お問い合わせください。
さらに、はじまりビジネスパートナーズの推奨する、全国の食品スーパーID-POS高速分析ツール「Real Shopper SM」をIT導入補助金を活用して、賢く導入してみませんか?IT導入補助金に関する特設サイトは以下をクリックしてください。

